Observe judges the stored response, so it needs a Comply retention rule on the calls you want scored. With no retention, content isn’t stored and there’s nothing to judge.
Set up a rule
Open Controls → Observe in platform.opper.ai and add a rule. Each rule is one judge running on its own. Several rules can match the same call, and they all fire. A rule has four choices. 1. Judge: the model that runs the check.
2. Sample: how often to check.
3. Score type: what kind of answer the judge gives.
4. Criteria: what “good” looks like. Free text up to 4096 characters. Required for Binary, optional for Score.
Where it applies
Rules at different scopes can overlap; all matching rules fire. There’s no priority.
Where you see the result
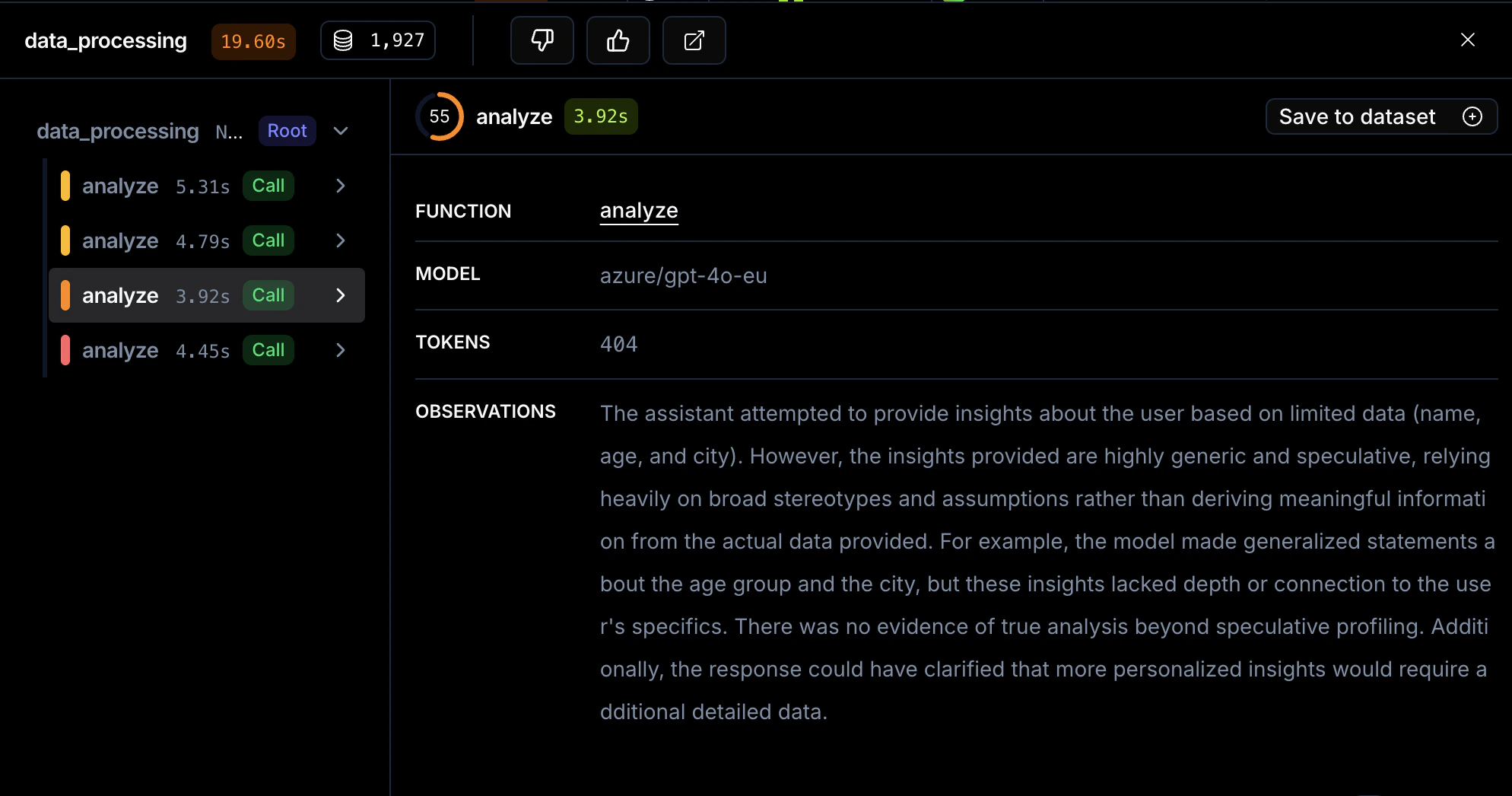
On the call’s trace span, an Observations row shows the judge’s commentary as markdown, with a collapsible Scorer Breakdown beneath it that lists each criterion’s pass/fail and reasoning. In the Controls section of the same span, an Observe event appears with an Eye icon, the rule name, status Passed or Flagged, and a scope badge (Org-level or Project-level).